画像解析AI「Deep Inspection」

概要
さまざまな業種に対応するAI画像検査システム
画像解析AI(Deep Inspection)では、画像の中で特定のパターンに一致する箇所を認識し、そのパターンが基準を満たしているかどうかを判断します。
「人間では判断できるが、画像処理システムではうまく判別できない」
そのような対象に対し、Deep Learningを用いることで、ひとの感覚のような柔軟な分類を行います。
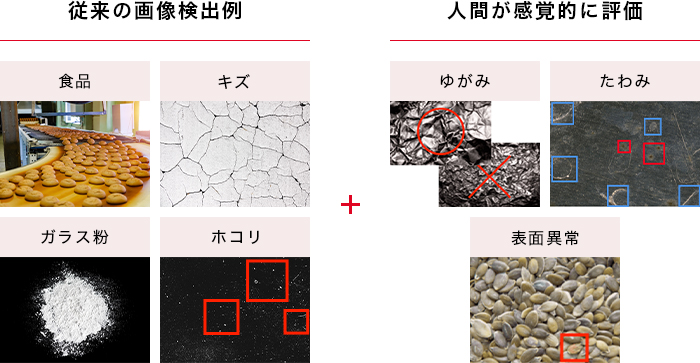
Deep Learningによる画像検出
従来の画像検出に加え、人間が感覚的に行う評価を兼ね備えています。

特長
自信度を付加した判定
過去の結果と比較し自信度を算出。自信度の高いものは自動検査へ、低いものは人に委ねる仕組みです。低い自信度のものだけ目視検査することで、確実に負荷を軽減し、精度を飛躍的に高めます。
継続運用でレベルアップ
人が経験を積むように、Deep Learningは学習データが増えるほど判定精度が上がります。継続的な運用で経験を積んだAIは、熟練の職人のように頼れるシステムになります。
既存ラインへ導入可能
私たちの製品はパッケージではなく、現在のラインを生かしたシステムを提案しています。さまざまな現場に合わせて設計し、長期間の運用とアップグレードを視野に入れた製品を提供しています。
導入の流れ
01.調査・分析
お客さまの製品、既存製造ラインへの導入、新規構築など、目的に合わせた導入方法を立案いたします。
メール・テレビ電話・面談等でのご相談を通じて、ご要望や大まかな現場の状況から実現の可能性を検討いたします。まずはお気軽にお問い合わせください。
02.システム設計
お客さまの現場に合わせてデータ収集を行い、最適なAI学習アルゴリズムを考案。プロトタイプ開発を経て本開発・納品いたします。
必要に応じてハードウエアを始めとした各分野の企業との協業を行い、特殊な検査にも対応できるハードウエアの設計・開発も行います。
03.効果測定・検証
構築したラインを実際に動かしながら効果測定・検証を行い、AIプログラムがフルにパフォーマンスを発揮できるようチューニングを行います。
04.システムの運用開始
導入後はご希望があれば、AI追加学習などサポートもいたします。
より高度な検査へのご相談、開発も行っています。
活用例
製造業で活躍する画像解析AIの例

外観検査
良品学習AIによる、熟練者の目視検査を再現することができます。

物体認識
物体認識AIアルゴリズムによって、協働ロボットの"目"の開発をすることができます。

水質検査
水質をAIが監視し、カメラを通して浮遊物・泡・波の状態のリアルタイム監視をすることができます。
製造業以外で活躍する画像解析AIの例

書籍の背表紙の読み取りAI
書籍の背表紙を撮影し、画像解析AIに文字認識させることで在庫管理が容易にできます。

建物検査における
外壁クラックAI画像診断
建物の外壁の劣化を撮影し、画像解析AIにより、外壁の修復や建て直しの判断をすることができます。

数量検品AI
規格品の中でも見た目にばらつきがある商品に対し、その商品の数を正確にカウントすることができます。
「Deep Inspection」は株式会社Ristの商標または登録商標です。株式会社RistはKCCSのグループ会社です。
画像認識AI「Labellio」はサービス提供を終了しました。画像AIに関連するお問い合わせは当ページにて承ります。